
GRPO
↻ ◁ |⚙⌨⚙| ▷ ↺
I have found that a lot (if not most) of people are using TRL as their base for GRPO experiments and many have had problems with it one way or another, to the point where I’ve seen comments such as:
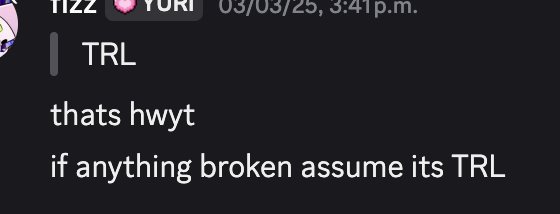
or
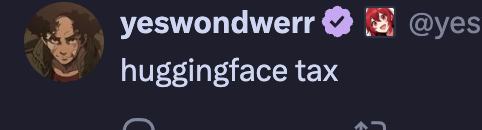
see this thread, for instance.
It’s also a bit of a bottleneck in downstream development. For instance, in the verifiers repo there’s a (now closed) issue to support VLM1. Will Brown, the maintainer, said:
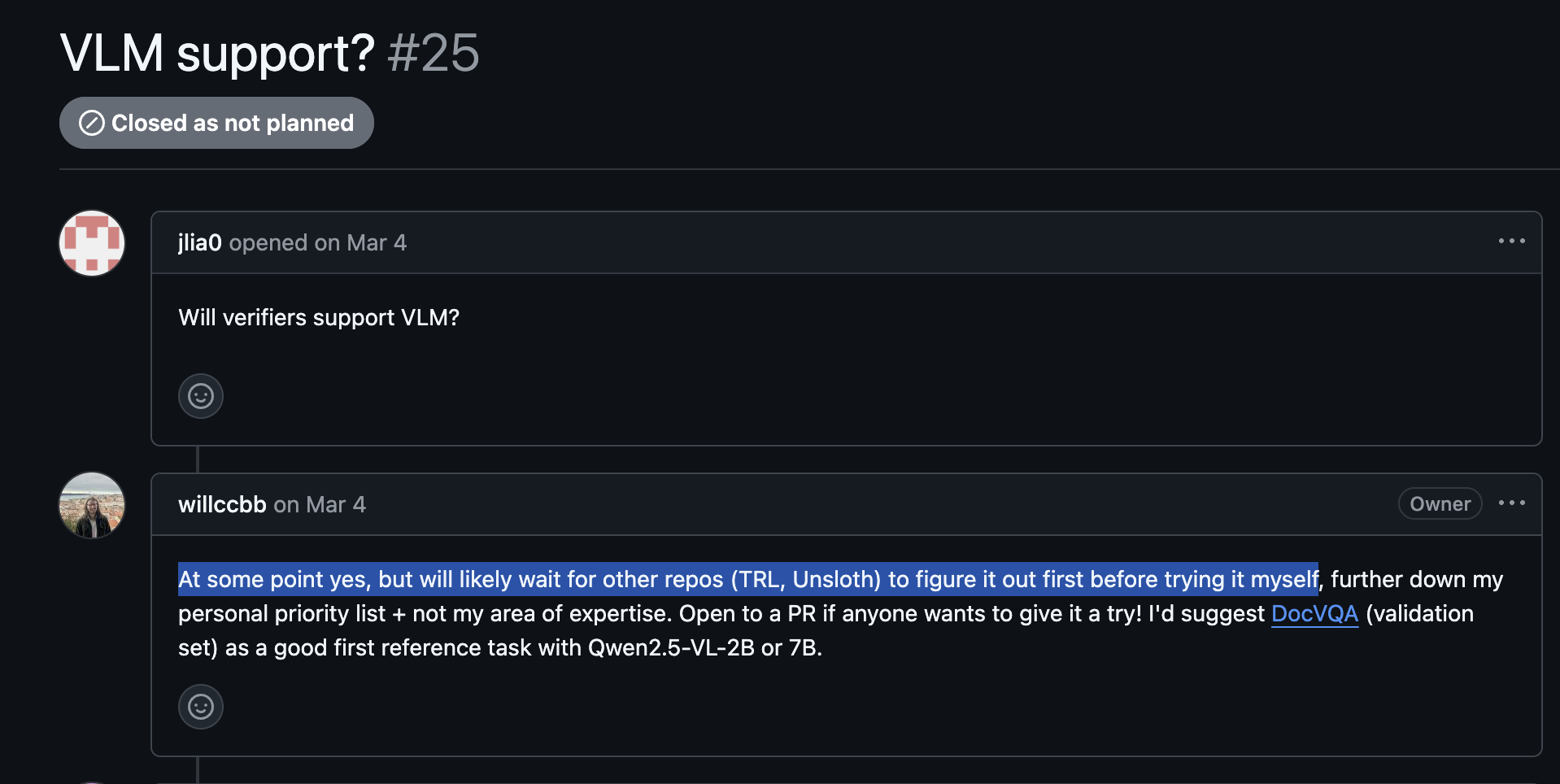
And in TRL there’s an open PR to add support for VLMs, but it has not moved at all in a while. Quentin Gallouédec, the maintainer, said:
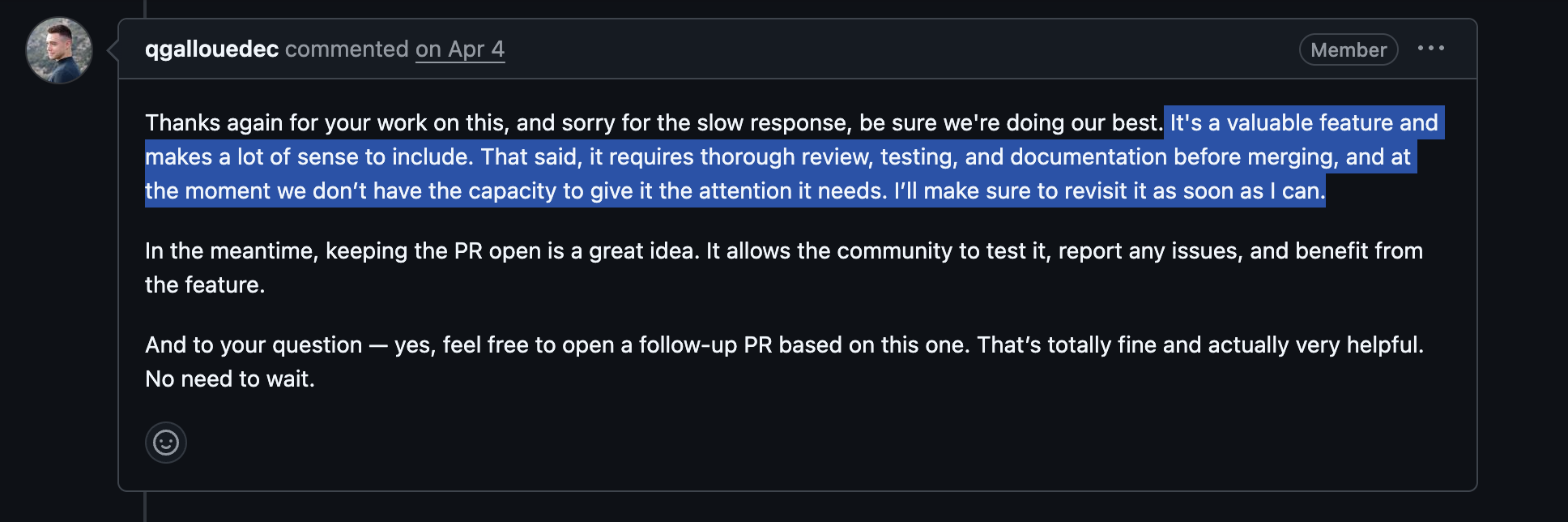
Even though in a twitter poll posted by him, VLM support came out on top as a desired feature:
What should be our next main priority for TRL?
— Quentin Gallouédec (@QGallouedec) May 6, 2025
Now, I know open source projects are hard to maintain, and, really, I have nothing but admiration for the folks at HF, especially Quentin, who maintains TRL. They provide a great service to the community; many of us (myself included) use their tools daily. However, I do think that framework developers tend to have an incentive to be crowd-pleasers and to be all-encompassing on features. In the specific context of RL for LLMs, which is rapidly changing, this can be very challenging.
So, we as a community end up in an uncomfortable situation where, if you want to run more contrived or interesting experiments, you end up in a trade-off between using something that works out-of-the-box with a set of features, but which might not be an exact fit for your needs or be hard to modify and so end up being limited by it, or a from-scratch implementation that could be a bit time-consuming but that could improve on the extensibility you need for your specific experiment idea.
In this post, I will try to show that, actually, the latter might not be a bad bet currently2.
Context
The reason I ended up doing this is because I, too, was looking for GRPO implementations that supported VLMs and in my search for them I found that many were TRL wrappers, like Groundlight’s r1_vlm, which is based on the GRPOTrainer class.
Then I noticed the PR I linked above, and even went ahead and did some experiments based on it, but then I saw it gained no traction and it was falling behind the work in the main branch.
So it looked like TRL wasn’t ready.
You might ask: why not other implementations? Well, there’s verl for instance, or forks of OpenRLHF like lmm-r1, but these two are also frameworks that have their own fair degree of complexity and I did not find them to be any more extensible/hackable than TRL.
Later on I think I saw this implementation: nano-aha-moment. I found it interesting because I noticed it was pretty self-contained and did not depend on other frameworks. However, it had two problems: it did not scale (it was designed to work on a single GPU) and it was written for LLMs without multimodal support.
I also found Brendan Hogan’s experiments, like this one which has multimodal support, but:
- it was built specifically for Qwen-VL
- it also didn’t have multi-gpu support
So, after seeing the state of these implementations, I decided to try to take the essence of TRL’s GRPOTrainer and implement it into one simple script, while trying to maintain simplicity and extensibility.
Before moving on to the actual details on the implementation I will do a brief outline of the GRPO algorithm. If you’re not interested in that, skip to the implementation section.
GRPO
It has now become clear that using RL on top of LLMs can enhance capabilities in certain domains. This is not a new concept, but OpenAI’s o-series and DeepSeek’s R1 model certainly has popularized its usage in verifiable domains, as an effective method to improve reasoning capabilities. Exactly how much RL to apply and how much compute it deserves remains an open question. What is clear is that RL-finetuning is well worth tinkering with.
The most popular implementation of RL in this context is probably GRPO, which was introduced in DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models.
The general idea is the following:
You want a model to get better at some task X, and you have a consistent, scalable way of verifying whether the model is indeed performing well at X. You ask the model to generate many completions for your task prompts, you score these completions with your verification method, and then update the model using the feedback of how well it did in each of the completions, relative to the other generations, keeping in mind that we don’t want to “update the model too much”.
Let’s disentangle these steps more clearly.
Generation
Assume we have a question/prompt \(q\). We send this prompt to the model to generate a set of \(G\) responses/completions \(\{o_{1}, o_{2}, ... o_{G}\}\)
Scoring
We compute the reward for each of these responses in a set \(\{r_{1}, r_{2}, ... r_{G}\}\) and then, we get the standardized/relative reward (aka advantage) of each of these wrt to the rest of the rewards:
\[\hat{A}_{i,t} = \frac{r_i - mean(r_1, r_2, ..., r_G)}{std(r_1, r_2, ..., r_G)}\]KL divergence
To keep our model close to a reference, we calculate the KL divergence between our model and the reference by using the unbiased estimator from Schulman et al. (2020):
\[\mathbb{D}_{\text{KL}}\left[\pi_\theta \|\pi_{\text{ref}}\right] = \frac{\pi_{\text{ref}}(o_{i,t} \mid q, o_{i,<t})}{\pi_\theta(o_{i,t} \mid q, o_{i,<t})} - \log \frac{\pi_{\text{ref}}(o_{i,t} \mid q, o_{i,<t})}{\pi_\theta(o_{i,t} \mid q, o_{i,<t})} - 1\]where \(\pi_{\theta}(o_t \mid q,o_{<t})\), called the policy, is the conditional probability distribution over the possible completions, given a prompt/question and the previous completions, parametrized by the model weights. This is just RL-notation for the notion of the token probabilities provided by the LLM.
Loss
Now, we can compute the loss using the above, as follows:
\[\mathcal{J}(\theta)= \frac{1}{G}\sum_{i=1}^{G}\, \frac{1}{|o_i|}\sum_{t=1}^{|o_i|} \Bigg\{ \min\!\Bigg[ \frac{\pi_{\theta}\!\bigl(o_{i,t}\mid q, o_{i,<t}\bigr)} {\pi_{\theta_{\text{old}}}\!\bigl(o_{i,t}\mid q, o_{i,<t}\bigr)} \,\hat{A}_{i,t}, \; \operatorname{clip}\!\Bigl( \frac{\pi_{\theta}\!\bigl(o_{i,t}\mid q, o_{i,<t}\bigr)} {\pi_{\theta_{\text{old}}}\!\bigl(o_{i,t}\mid q, o_{i,<t}\bigr)}, \,1-\varepsilon,\;1+\varepsilon \Bigr)\, \hat{A}_{i,t} \Bigg] \;-\; \beta\,\mathbb{D}_{\mathrm{KL}}\!\bigl[\pi_{\theta}\,\|\,\pi_{\text{ref}}\bigr] \Bigg\}\]Wrapping components into a full training loop, we end up with the following algorithm, as shown in the original DeepSeekMath paper:

Modifications
In DAPO: An Open-Source LLM Reinforcement Learning System at Scale it is argued that the original GRPO loss under-penalizes longer responses. TRL follows their recommendation to avoid this by setting the following as the default loss:
\[\mathcal{J}(\theta)= \frac{1}{\sum_{i=1}^G |o_i|} \sum_{i=1}^{G}\, \sum_{t=1}^{|o_i|} \Bigg\{ \min\!\Bigg[ \frac{\pi_{\theta}\!\bigl(o_{i,t}\mid q, o_{i,<t}\bigr)} {\pi_{\theta_{\text{old}}}\!\bigl(o_{i,t}\mid q, o_{i,<t}\bigr)} \,\hat{A}_{i,t}, \; \operatorname{clip}\!\Bigl( \frac{\pi_{\theta}\!\bigl(o_{i,t}\mid q, o_{i,<t}\bigr)} {\pi_{\theta_{\text{old}}}\!\bigl(o_{i,t}\mid q, o_{i,<t}\bigr)}, \,1-\varepsilon_{low},\;1+\varepsilon_{high} \Bigr)\, \hat{A}_{i,t} \Bigg] \;-\; \beta\,\mathbb{D}_{\mathrm{KL}}\!\bigl[\pi_{\theta}\,\|\,\pi_{\text{ref}}\bigr] \Bigg\}\]Other modifications are set as optional arguments in the TRL implementation. In this implementation I stick to the defaults, but for more information on the options check out this section in their docs.
Implementation
The full implementation can be found in my grpo repo. There’s instructions about how to use it in the README. Here, I will go over some important points that either overlap with TRL and are worth noting or differ from TRL’s implementation. Here are some highlights:
- To drop dependencies, I removed the reliance on accelerate and the deepspeed integration. Instead, I use PyTorch’s distributed features.
- My implementation only supports generation with vLLM as a separate process running in a server, unlike TRL which supports either co-locating the vLLM engine so as to share GPU memory with the training process or generating the completions without vLLM at all, in addition to running a separate server too.
- I skipped reward-weighing. This wouldn’t be hard to include and I might add it in the future, but, fwiw, in TRL no reward-weighing is also a default. It’s also not part of the original algorithms.
- One thing that is part of the original algorithms but I didn’t include is the \(\mu\) parameter (
num_iterationsin TRL). In TRL, this is also set to 1 by default, so my implementation should match TRL, but I think I would like to include this eventually.
Ok, now let’s go through some of the most relevant bits of the implementation in detail.
Config
The config is handled in the config.py module as a data class. It follows some of the same defaults as TRL:
@dataclass
class TrainConfig:
model_id: str = "Qwen/Qwen2.5-VL-7B-Instruct"
dataset_id: str = "HuggingFaceH4/rlaif-v_formatted"
collate_fn: Callable[[list[dict]], list[dict]] | None = None
no_apply_chat_template: bool = False
extra_columns: list[str] | None = None
batch_size: int = 2
max_completion_len: int = 256
num_generations: int = 2
num_epochs: int = 1
learning_rate: float = 1e-6
weight_decay: float = 0.0
warmup_ratio: float = 0.0
grad_norm: float = 1.0
epsilon: float = 0.2
epsilon_high: float = 0.2
beta: float = 0.04
temperature: float = 0.9
top_k: int = 50
use_peft: bool = False
use_fsdp: bool = False
bf16: bool = False
fsdp_bf16: bool = False
gradient_checkpoint: bool = False
log_steps: int = 1
save_steps: int = 5
use_wandb: bool = False
wandb_project: str = "YOUR_WANDB_PROJECT"
push_to_hub: bool = False
hub_repo_id: str = "YOUR_HUB_REPO_ID"
hub_private: bool = True
seed: int = 42
dtype: str = "float32"
use_cache: bool = False
Some things to note:
- A
collate_fncan be passed to the config that will be used by the dataloader. This can come in handy whenever we want to transform our batches without modifying the main training logic. For instance for Qwen2.5-VL we might want to use the qwen-vl-utils to process and integrate the visual data. no_apply_chat_templateis passed explicitly. This is handled with themaybe_apply_chat_templatefunction in-line . However, I opted for not including this util in the logic, which was just more code.- The
extra_columnsvalue is also not in TRL. My idea for this was that if your dataset has other columns you care about, apart from the prompts (and the images in the multimodal case) then you could define which ones you wanted to include in the dataset constructor. That way, with a little bit more work, they could be passed-on to the reward functions or be used at some other point in the code. batch_sizewould be the equivalent ofper_device_train_batch_sizein TRL.
I think the rest of the values are pretty self-explanatory, or are documented in TRL.
Model init
Although this part is conceptually easy, it has a lot of paths, depending on which features are enabled. I’ll try to explain the main branches.
The loading of the models is handled in the function init_models. There are two models we load: the policy model (i.e. the one we update) and the reference model (for the KL divergence estimate). There are also two main configuration modes which we care about when loading: FSDP usage and PEFT usage. Let’s have a look at the combinations.
Policy model
DDP
In the baseline case we use DDP. We first load the model as we would usually do, using the .from_pretrained method in transformers. One difference here with TRL is that we use a smart_load function in the utils which basically just handles the different ways in which you could load a model in transformers (e.g. Qwen2.5-VL is loaded differently than Qwen2.5). Then we wrap the model with DDP. That is, something as follows:
policy_model_unwrapped = smart_load(
cfg.model_id, use_cache=cfg.use_cache, torch_dtype=cfg.dtype
)
policy_model_unwrapped.to(device)
policy_model = DDP(
policy_model_unwrapped,
device_ids=[local_rank],
output_device=local_rank,
find_unused_parameters=True if cfg.gradient_checkpoint is False else False,
)
PEFT
If using PEFT, then we also load the model with smart_load but then we also use the get_peft_model function. Finally, we wrap this with either DDP or FSDP:
policy_model_unwrapped = smart_load(
cfg.model_id, use_cache=cfg.use_cache, torch_dtype=cfg.dtype
)
lora_config = LoraConfig(
lora_alpha=64,
lora_dropout=0.05,
r=32,
bias="none",
target_modules=["q_proj", "v_proj"],
task_type="CAUSAL_LM",
)
policy_model_unwrapped = get_peft_model(policy_model_unwrapped, lora_config)
Then, either:
policy_model_unwrapped.to(device)
policy_model = DDP(
policy_model_unwrapped,
device_ids=[local_rank],
output_device=local_rank,
find_unused_parameters=True if cfg.gradient_checkpoint is False else False,
)
or…
FSDP
If we’re using FSDP then the model to be wrapped is either a base model or a peft model. In both cases:
policy_model = FSDP(
policy_model_unwrapped,
device_id=local_rank,
sharding_strategy=ShardingStrategy.FULL_SHARD,
use_orig_params=True,
mixed_precision=mixed_precision,
sync_module_states=True,
)
Ref model
Handling the model ref model is slightly simpler.
DDP
In the case of DDP we only need to copy the initial policy model (before updating it). We call the function create_reference_model from the utils. This just makes a deep copy of the model, and then sets requires_grad to False for the copy and sets it to eval mode, as we won’t be updating it.
PEFT
The case of PEFT is even simpler! The PEFT API allows us to merge and unmerge the adapters to the base model. So, instead of loading a new model, we can set the ref model to None and just call merge_adapter/unmerge_adapter or disable_adapter whenever we need it.
FSDP
When using FSDP we can’t directly merge/unmerge the adapters, so we need to load the model (which we do with smart_load) and then wrap it with FSDP, but set it to eval mode, again, as we won’t be making updates to it3.
Generation server
As I mentioned above, this implementation uses vLLM to generate the completions. This has the benefit that it is a fast and efficient serving library, and it can scale in tandem with the rest of the code with tensor parallelism.
This part of the code is almost exactly the same. There’s a vllm_server.py script that runs in the background and a client that is initialized in the server.
These are almost identical to TRL’s. The only things I changed were:
- dropped pydantic, again just to reduce dependencies.
- I convert the images from PIL images to base64 in the client and convert back from base64 to PIL images in the server4.
I actually did not want to do the latter, and perhaps there is a workaround, but I found that if, for instance, in the case of Qwen2.5-VL, if you want to call the process_vision_info function from the qwen-vl-utils library, you will always have PIL images as inputs. These can’t be communicated from the client to the server because they are not serializable.
Weight-updates
The generation server must use the latest weights to generate the completions. To do this, we must sync the weights at each step. This is handled by the update_vllm_client function 5. This function also has different behavior depending on the config values.
Baseline
If using DDP, the update_vllm_client receives a base model, in which case it iterates over the params and calls the update_named_param method from the client, like so:
if rank == 0:
for name, param in model.named_parameters():
vllm_client.update_named_param(name, param.data)
PEFT
If using PEFT and no FSDP, then we:
- merge the adapter
- send the merged params
- unmerge the adapter
Something roughly like this:
model.merge_adapter()
for name, param in model.named_parameters():
# some fixes to the param names here then:
if rank == 0:
vllm_client.update_named_param(name, param.data)
model.unmerge_adapter()
FSDP
If using FSDP, then either with or without PEFT we call the function defined in the utils as sync_fsdp_params_to_vllm. This function does an efficient post-order traversal of the module tree and calls the summon_full_params context manager to gather the parameters of that module and then iterate over the parameters to send them. If PEFT is enabled then we merge the adapter at the module level, then call update_named_param and finally unmerge the adapter.
The difference here with TRL is that in TRL the parameters are gathered with a special deepspeed context manager. I’m not sure that this is particularly memory-efficient if the model is very big because in theory it would unshard all the params into at least one of the GPUs to be able to call model.merge_adapter(), though, admittedly, I haven’t gone into the details. For my implementation I decided to iterate the modules, gathering and only then merge each one, instead of gathering all the params, then merging the adapter to the whole model6.
Omitting some details, the code looks ~ like this:
def sync_fsdp_params_to_vllm(
module: nn.Module,
vllm_client: VLLMClient | None,
prefix: str = "",
visited: set[str] | None = None,
peft: bool = False,
) -> None:
rank = dist.get_rank()
if visited is None:
visited = set()
for child_name, child_module in module.named_children():
# recursive call
sync_fsdp_params_to_vllm(
child_module, vllm_client, prefix=child_prefix, visited=visited, peft=peft
)
if isinstance(module, FSDP):
with FSDP.summon_full_params(module, recurse=False, writeback=False):
merged = []
if peft:
for m in module.modules():
if isinstance(m, LoraLayer):
m.merge()
merged.append(m)
for param_name, param in module.named_parameters():
# fixes to the param names here
if rank == 0:
vllm_client.update_named_param(full_name, param.data)
for m in merged:
m.unmerge()
Scoring
There aren’t too many differences between the way in which TRL scores the completions and the way I do so in my implementation.
One thing that is different is that I separated this logic into its own function, called score_completions.
Also, in the TRL implementation we have:
rewards = (rewards_per_func * self.reward_weights.to(device).unsqueeze(0)).nansum(dim=1)
This is to apply the reward weights from the config. I didn’t include a config value for the weights, so it’s always just:
rewards = rewards_per_func.nansum(dim=1)
Another thing is that I always scale the advantages:
advantages = (rewards - mean_grouped_rewards) / (std_grouped_rewards + 1e-4)
In TRL, you can optionally disable it:
if self.scale_rewards:
advantages = advantages / (std_grouped_rewards + 1e-4)
Loss
The computation of the loss is also pretty much the same, except, as I said earlier, I always use the following:
loss = (per_token_loss * completion_mask).sum() / completion_mask.sum().clamp(
min=1.0
)
whereas in TRL there are more options:
if self.loss_type == "grpo":
loss = ((per_token_loss * completion_mask).sum(-1) / completion_mask.sum(-1).clamp(min=1.0)).mean()
elif self.loss_type == "bnpo":
loss = (per_token_loss * completion_mask).sum() / completion_mask.sum().clamp(min=1.0)
elif self.loss_type == "dr_grpo":
loss = (per_token_loss * completion_mask).sum() / (per_token_loss.size(0) * self.max_completion_length)
else:
raise ValueError(f"Unknown loss type: {self.loss_type}")
Data sampling
One last thing that differs from the TRL implementation is that TRL prepares the dataloader by leveraging accelerate. It does:
return self.accelerator.prepare(DataLoader(train_dataset, **dataloader_params))
On the other hand, in my implementation there is no accelerate, so instead we:
sampler = RepeatSampler(
data_source=dataset,
mini_repeat_count=cfg.num_generations,
batch_size=(world_size * cfg.batch_size) // cfg.num_generations,
repeat_count=1,
shuffle=True,
seed=cfg.seed,
)
batch_sampler = build_batch_sampler(
sampler=sampler,
batch_size=cfg.batch_size,
num_replicas=world_size,
rank=rank,
)
return DataLoader(
dataset=dataset,
batch_sampler=batch_sampler,
collate_fn=cfg.collate_fn,
num_workers=0,
pin_memory=True,
)
by calling the build_batch_sampler function from the utils. This builds the distributed batch sampler needed, while removing a lot of complexity from the accelerate library which is not really relevant here.
VLM support
There really aren’t too many changes related to the VLM support, actually, and they were definitely easier to implement once the train code was stripped-down of irrelevant edges. Having said that, most of the relevant changes are already present in the PR I linked above, so I think TRL is really not too far from having this too. The most relevant changes, apart from the vllm client/server updates I mentioned above are the following, in the prepare_inputs func:
images = [x["images"] for x in batch if "images" in x]
if len(images) == 0:
images = None
if images is None:
prompt_inputs = processor(
text=prompts_text.copy(),
return_tensors="pt",
padding=True,
padding_side="left",
add_special_tokens=False,
).to(device)
# more stuff here
vllm_prompts = [
{"multi_modal_data": {"image": image}, "prompt": prompt}
for prompt, image in zip(
all_prompts_text[:: cfg.num_generations],
all_images[:: cfg.num_generations],
)
]
else:
vllm_prompts = all_prompts_text[:: cfg.num_generations]
The idea is just that if we’re using a multimodal model we should pass the images to the processor and then send them to the vLLM server! Simple as. There are a couple of minor changes because now the processor has a tokenizer attribute whereas in the text-only case we just used the processor directly, but, really, it’s not much else.
To-dos
As a final note I would just like to write down some pending things for this implementation, some of which I had already thought about and others I noted while writing this 😂. I hope to come back soon enough to tackle them:
- add
num_generationsas a parameter - add flash attention in the model init
- add evaluation loop
- print completions
Conclusion
The main training script has ~600 LoC, around 40% of the grpo_trainer.py module in TRL. This is not at all a replacement for TRL+accelerate+deepspeed, but, rather, an exercise that hopefully shows, firstly, that it is definitely possible to run GRPO in a scalable way w/o accelerate and deepspeed by just leveraging pytorch’s API, and, secondly, that it’s easier to add features (like VLM support) when doing things like this. Two good take-aways, I’d say, and hopefully they won’t be the last ones :)
The full code is here.
🍀
-
Though this might change soon with the refactor work that Will is doing 🙌 ↩
-
I say currently because this might change in the future. It’s likely that development/research will stabilize around specific methods/techniques. Who knows, but I suspect that something like this will happen eventually. ↩
-
I do wonder whether there’s a way to use FSDP+PEFT more efficiently. You can’t call merge/unmerge on the FSDP model, but perhaps it’s possible to post-order traverse the modules and call merge on each module while the params are gathered. There’s a similar trick when syncing the weights in the vLLM server, but I haven’t explored this much. I hope to do so in the future. ↩
-
I’m thinking maybe it’d be cool to change this to be bytes and avoid the 33% overhead in base64, but I’m not sure if it’s worth it, given that the number of images are potentially low. I might add it as a to-do, though. ↩
-
I’m thinking I’m going to rename this to
update_vllm_server, which makes more sense. ↩ -
When I ran some tests I had trouble running both FSDP and PEFT in the TRL trainer. I got an error with the following message
RuntimeError: inconsistent tensor size. ↩